
Java Preferences API
java.util.prefs.Preferences API is available in Java since 1.4. Here is an example:
import java.util.prefs.Preferences;
public class Example {
public static void main(String[] args) {
Preferences root = Preferences.userRoot().node("name").node("kropp");
root.putInt("birth_year", 1986);
root.put("camelCase", "String/Value");
root.node("sub_node").putBoolean("enabled", true);
System.out.println(root.getInt("birth_year", 0));
}
}
Java somehow stores given key-value pairs organized in a tree structure on a user’s computer. On every operating system, it uses native APIs to do this. So values are stored in Registry on Windows, in .plist on Mac and in XML files on others systems (primarily, Linux). Although, you shouldn’t really care about it, because it just works.
But only until you need to access these settings from outside Java Virtual Machine. In my case, I needed to read/write these values from C++. So I started to investigate how it is implemented in JRE and reimplement the same in C++. Here is what I’ve found.
Mac OS
Let’s start with the simplest case. On Mac OS X preferences are stored in dictionaries in .plist you can list them quite easily:
$ defaults read ~/Library/Preferences/com.apple.java.util.prefs.plist /
{
"name/" = {
"kropp/" = {
"birth_year" = 1986;
camelCase = "String/Value";
"sub_node/" = {
};
};
};
}
Have you noticed slashes at the end of each key? For some reason Mac implementation doesn’t remove node separator even though nodes are already nested. However the biggest problem is that Preferences daemon caches these values and you’re in trouble if you read/write them not using standard APIs. The best advice on how to overcome this issue was: killall cfprefsd
Ouch.
Windows
Registry keys are nested too, but Windows JRE developers have removed unnecessary slashes. Right before they would apply some fancy encoding to both keys and values.
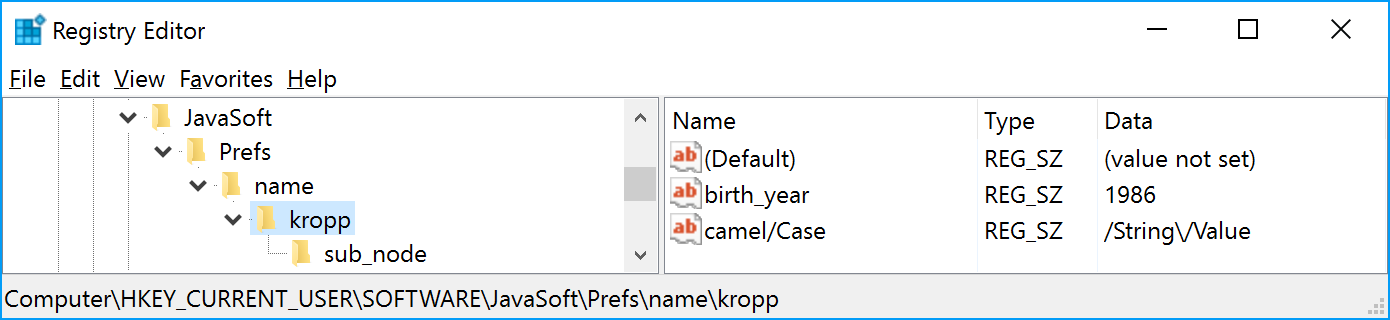
Comment in Javadoc explains why do they did this.
/**
* Converts value string to it Windows representation.
* as a byte-encoded string.
* Encoding algorithm adds "/" character to capital letters, i.e.
* "A" is encoded as "/A". Character '\' is encoded as '//',
* '/' is encoded as '\'.
* Then encoding scheme similar to jdk's native2ascii converter is used
* to convert java string to a byte array of ASCII characters.
*/
private static byte[] toWindowsValueString(String javaName) {
// …
}
Do you understand? Me neither.
Linux
But my favorite implementation is on Linux. At first sight it is the cleanest and the most obvious one:
$ cat ~/.java/.userPrefs/name/kropp/site/prefs.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE map SYSTEM "http://java.sun.com/dtd/preferences.dtd">
<map MAP_XML_VERSION="1.0">
<entry key="birth_year" value="1986"/>
<entry key="camelCase" value="String/Value"/>
</map>
Up until you store a key in a node with underscore in its name. Then something really awkward happens:
$ ls ~/.java/.userPrefs/name/kropp/
_!(:!d@"i!&8!bg"v!'@!~@== prefs.xml
This cryptic _!(:!d@“i!&8!bg"v!’@!~@== is actually “birth_year”. What happened to it? Let’s again take a look into Java sources:
/**
* Returns true if the specified character is appropriate for use in
* Unix directory names. A character is appropriate if it's a printable
* ASCII character (> 0x1f && < 0x7f) and unequal to slash ('/', 0x2f),
* dot ('.', 0x2e), or underscore ('_', 0x5f).
*/
private static boolean isDirChar(char ch) {
return ch > 0x1f && ch < 0x7f && ch != '/' && ch != '.' && ch != '_';
}
/**
* Returns the directory name corresponding to the specified node name.
* Generally, this is just the node name. If the node name includes
* inappropriate characters (as per isDirChar) it is translated to Base64.
* with the underscore character ('_', 0x5f) prepended.
*/
private static String dirName(String nodeName) {
for (int i=0, n=nodeName.length(); i < n; i++)
if (!isDirChar(nodeName.charAt(i)))
return "_" + Base64.byteArrayToAltBase64(byteArray(nodeName));
return nodeName;
}
The encoding used appears to be Base64, but some alternative one. This is because in original Base64 there are both lower and upper case characters, which are indistinguishable on some file systems.
When you look at it again, this is really crazy: if there is an underscore in a node name, it is encoded, and as a final step underscore is prepended. What?!
Conclusion
Cross-platform programming is hard.
Subscribe to all blog posts via RSS